The quality of reports on garmin connect is disappointing to say the least. Some things I wanted:
- Daily/Weekly over time. Garmin has fixed presets. At 6 months or a year, you only get monthly counts.
- Control the date range - Garmin has week, month, 6 month, year fixed views, and fixed buckets in said views.
- Exclude my commute rides. It skews the averages. What is my cadence/pace on only >20km bike rides?
- It would be fun to do.
Unfortunately Garmin charges(!) to use their API. Disappointing. The simplest method for data I found was to manually export(20 events at a time..) from garmin connect. This gave me a bunch of .csv files to work with.
Initially I tried to just use a file input on logstash with the csv filter. Unfortunately Garmin is not consistent with it's data formats in events. The biggest issue were pace/speed fields varying. "1:50 min/100 m" - swimming, "15.6" (kph) - cycling/rowing/some swimming, or "4:30" (4:30/min km) - running/walking.
I ended up writing a python parser to do the following:
- Read conf file indicating format of csv/important fields for each activity type in the csv
- Convert fields into usable formats for Kibana graphing
- Generate json logging/send to Logstash 'ready to go' for ES/Kibana.
The current version of the parser is here . It's rough, but works. Imported all 377 activities from my garmin account going back 2.5 years. Including some that were initially imported from run keeper to garmin, resulting in very odd formatting.
Now that I have the initial import working, i'll add a check against ES to prevent sending a duplicate activity to ES during imports. Ideally i'll find a way to automate fetching the 'last 20' events csv daily, but worst case i'll feed the script a fresh csv once a week.
Example .csv from garmin connect:
Untitled,Lap Swimming,"Wed, Jun 10, 2015 4:44",18:51,"1,000 m",240,--,--,1:53 min/100 m,1:33 min/100 m,--,--,--,--,480,--,12,--,--,40,
Stockholm Running,Running,"Wed, Jul 15, 2015 6:43",37:20,8.07,615,28,5.0,4:37,3:18,177,194,--,--,--,84,--,--,--,--,
SATs,Treadmill Running,"Tue, Jan 26, 2016 17:41",25:01,5.51,466,0,5.0,4:32,4:20,174,194,--,--,--,81,--,--,--,--,
Stockholm Cycling,Cycling,"Thu, Jul 16, 2015 6:33",3:07,1.15,36,6,--,22.1,25.5,--,--,--,--,--,--,--,--,--,--,
Untitled,Walking,"Sat, Sep 20, 2014 8:19",23:07,2.29,165,28,--,10:35,2:25,--,--,--,--,--,--,--,--,--,--,
Untitled,Rowing,"Tue, Sep 16, 2014 15:23",--,2.60,154,--,--,14.2,--,--,--,--,--,--,--,--,--,--,--,
Untitled,Strength Training,"Tue, Jul 14, 2015 6:42",22:11,0.00,0,0,--,0.0,--,--,--,--,--,--,--,--,--,--,--,
Open Water Swim -Tri,Open Water Swimming,"Sun, Aug 23, 2015 9:00",29:41,1.65,383,--,--,3.3,--,--,--,--,--,--,--,--,--,--,--,
Configuration for the parser:
[config]
csv_order: Activity Name,Activity Type,Start,Time,Distance,Calories,Elevation Gain,Training Effect,Avg Speed(Avg Pace),Max Speed(Best Pace),Avg HR,Max HR,Avg Bike Cadence,Max Bike Cadence,sumStrokes,Avg Run Cadence,Avg Strokes,Min Strokes,Best SWOLF,Avg SWOLF
csv_integers: Calories,Elevation Gain,Avg HR,Max HR,Avg Bike Cadence,Max Bike Cadence,sumStrokes,Best SWOLF,Avg SWOLF
csv_floats: Distance,Training Effect,Avg Speed(Avg Pace),Max Speed(Best Pace)
[activities]
Cycling_fields: Activity Name,Activity Type,Start,Time,Distance,Calories,Elevation Gain,Training Effect,Avg Speed(Avg Pace),Max Speed(Best Pace),Avg HR,Max HR,Avg Bike Cadence,Max Bike Cadence,sumStrokes
Lap Swimming_fields: Activity Name,Activity Type,Start,Time,Distance,Calories,Avg Speed(Avg Pace),Max Speed(Best Pace),Avg HR,Max HR,sumStrokes,Avg Strokes,Min Strokes,Best SWOLF,Avg SWOLF
Open Water Swimming_fields: Activity Name,Activity Type,Start,Time,Distance,Calories,Avg Speed(Avg Pace),Max Speed(Best Pace),Avg HR,Max HR,sumStrokes,Avg Strokes,Min Strokes,Best SWOLF,Avg SWOLF
Strength Training_fields: Activity Name,Activity Type,Start,Time,Calories,Avg HR,Max HR
Running_fields: Activity Name,Activity Type,Start,Time,Distance,Calories,Elevation Gain,Training Effect,Avg Speed(Avg Pace),Max Speed(Best Pace),Avg HR,Max HR,Avg Run Cadence
Key things:
- csv_order: Since you can order/choose fields in garmin, needed to specify the order they will be in.
- csv_integers/floats: Fields from the csv that should become an integer/floats, otherwise you can't do math in Kibana/ES
- *_fields: fields for each activity type. The csv will put '--' in each field with no data/irrelevant, to prevent extra fields/cast issues in ES I ommit the fields that aren't relevant to each activity.
I will add host/port for the udp logger and some other parameters when I go back to clean up the initial script.
The relevant logstash configuration was:
input {
udp {
port => 6400
codec => "oldlogstashjson"
type => "garmin"
workers => 5
}
}
output {
if [type] == "garmin" {
elasticsearch {
hosts => ["localhost:9200"]
index => "garmin-%{+YYYY.MM.dd}"
template => "/opt/logstash-custom/templates/garmin.json"
template_name => "garmin"
}
}
}
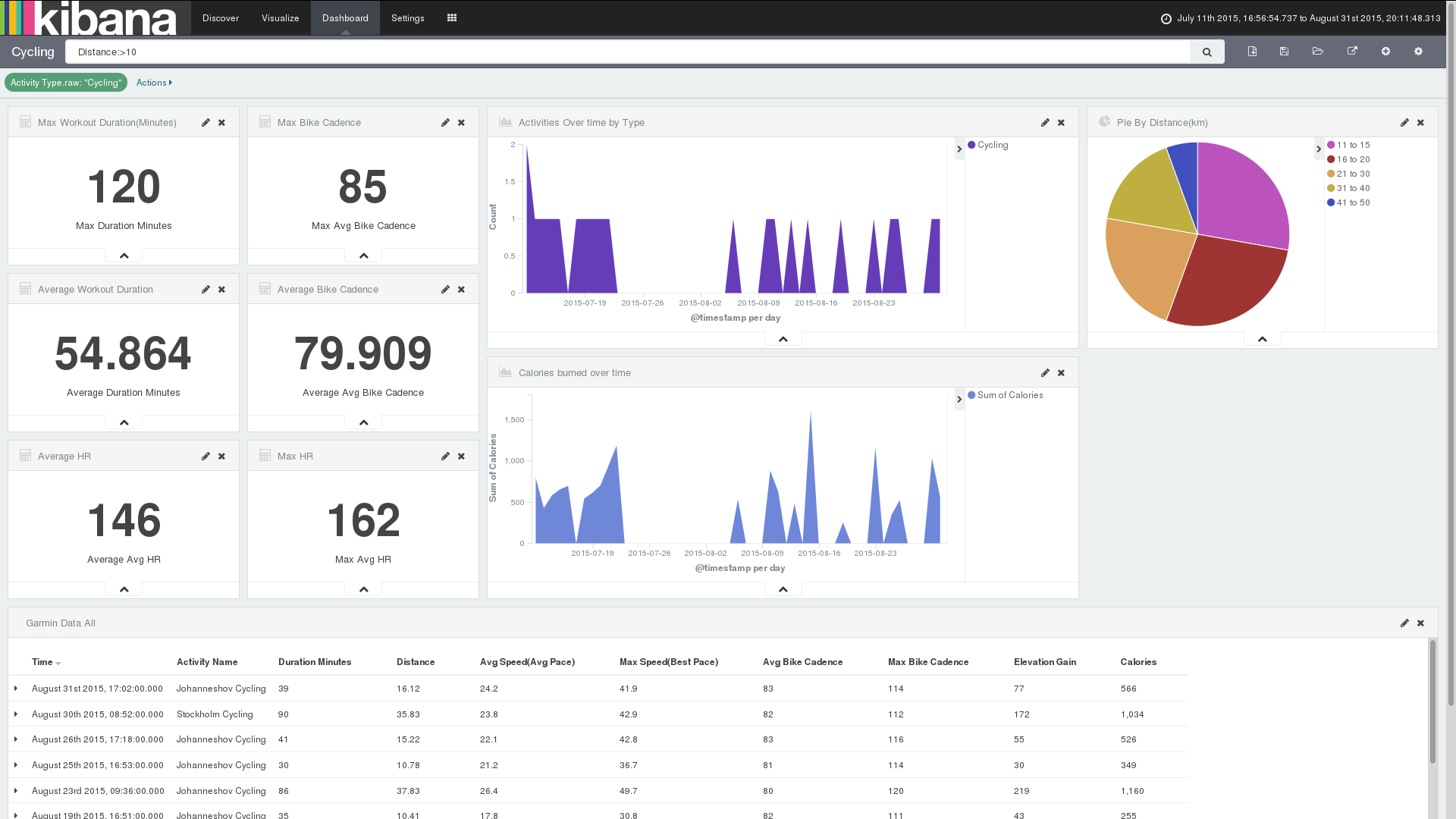
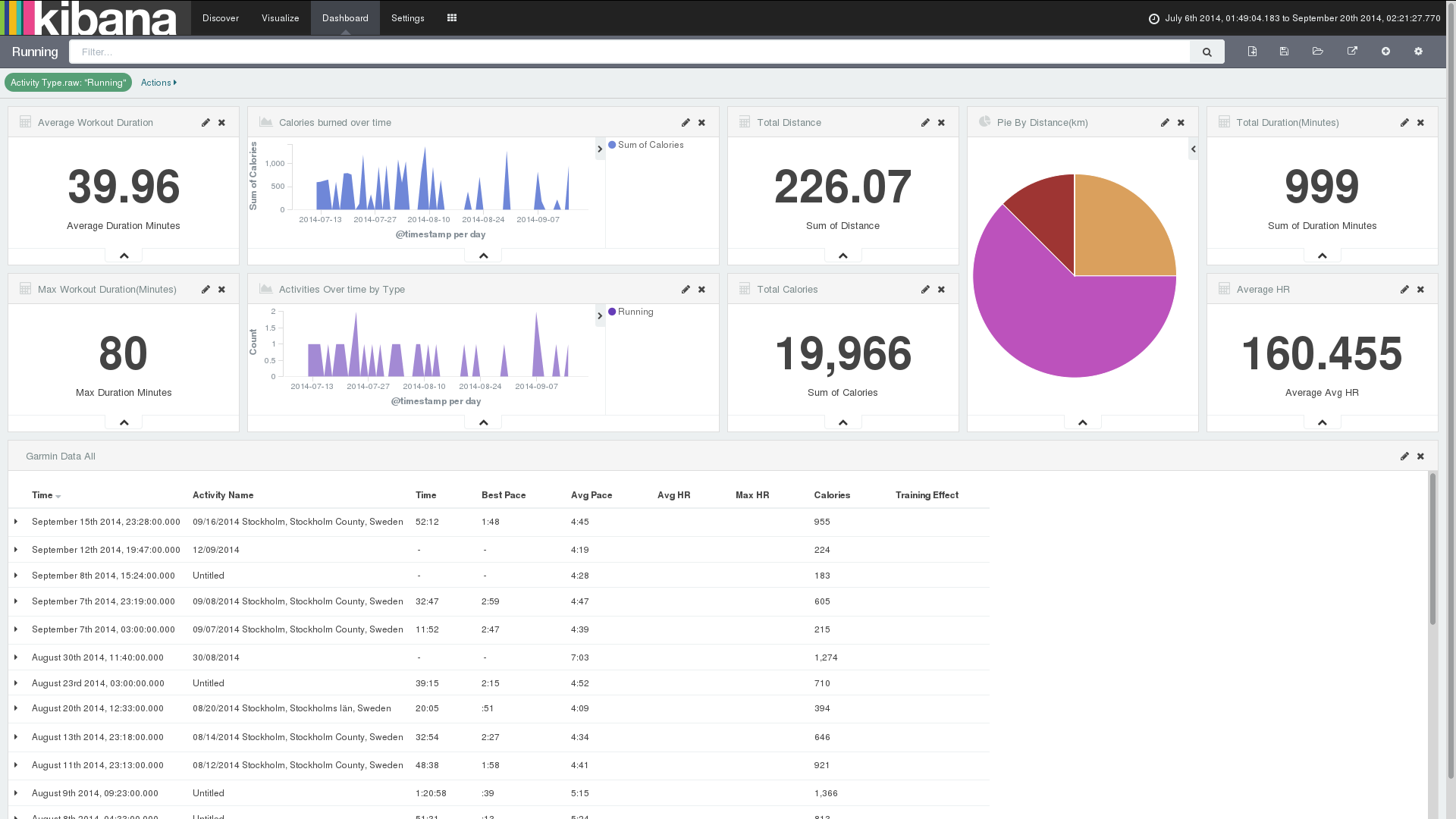
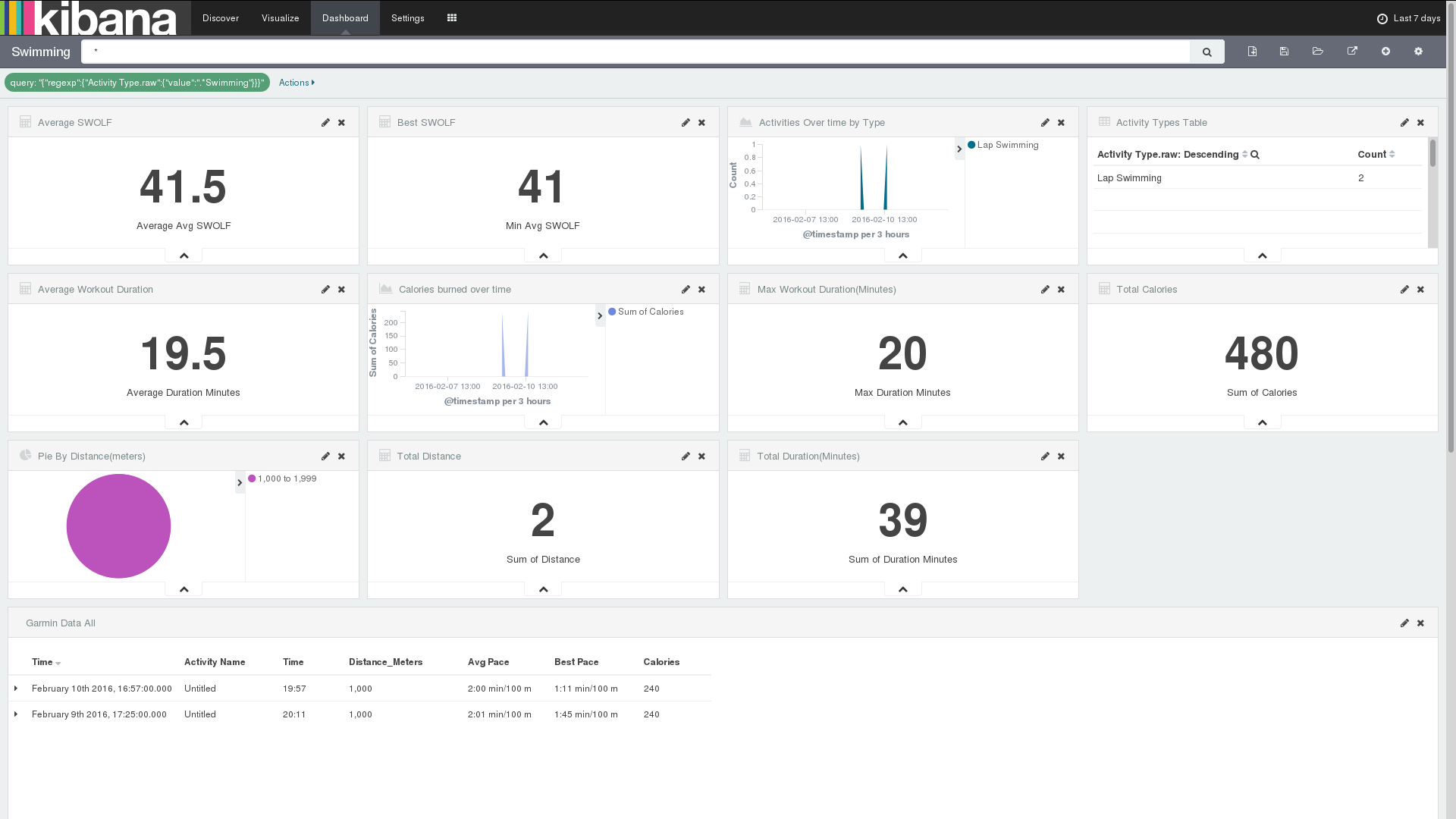
The result is what I wanted. I can exclude all of the < 15km bike rides from my overall stats, specify my own ranges/buckets, etc:

Also created views for each activity.
Cycling:
Running:
Swimming:
more ...